一個(gè)強(qiáng)化學(xué)習(xí)算法包括以下幾個(gè)部分:Model、Policy、Value Function。對(duì)于Model,如果是馬爾科夫決策過(guò)程(MDP),一般包括狀態(tài)轉(zhuǎn)移的概率模型,以及一個(gè)Reward Model,也就是獎(jiǎng)勵(lì)的模型。其實(shí)不難理解,既然涉及到馬爾科夫鏈,那一般就有轉(zhuǎn)移概率矩陣;另外這是決策模型,每次決策對(duì)應(yīng)有獎(jiǎng)勵(lì),所以還有一個(gè)獎(jiǎng)勵(lì)模型。另外,馬爾科夫鏈的轉(zhuǎn)移概率也會(huì)涉及到?jīng)Q策,比如:

其中s_t是當(dāng)前狀態(tài),s是state的意思,a_t是當(dāng)前的決策,a是action的意思,它的意思就是一個(gè)條件概率,如果當(dāng)前狀態(tài)是s,當(dāng)前決策是a,那么下一次狀態(tài)到s'的概率是多少呢?就是這個(gè)條件概率。
另外,做了這個(gè)決策,還要獲得相關(guān)的獎(jiǎng)勵(lì),也就是reward,那么應(yīng)該是多少呢?本質(zhì)上是一個(gè)條件期望:
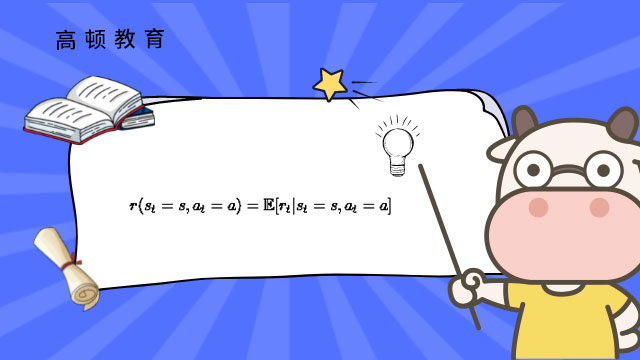
它的意思也很顯然,就是當(dāng)前狀態(tài)是s,當(dāng)前決策是a的情況下,當(dāng)前的reward(假設(shè)為r_t)的期望是多少的意思。
為什么要用到期望呢?因?yàn)橛袝r(shí)候這個(gè)獎(jiǎng)勵(lì)具有隨機(jī)性。
例如現(xiàn)在的狀態(tài)是高三了,可以選擇出國(guó),可以選則參加高考;如果選擇出國(guó),這是action,但對(duì)應(yīng)的結(jié)果也是隨機(jī)的,可能申請(qǐng)到這所學(xué)校,可能申請(qǐng)到那所學(xué)校;比如申請(qǐng)到前10的概率是10%,申請(qǐng)到前50的概率是50%,或許最終的期望就是申請(qǐng)到第50名左右的學(xué)校。因此,不是說(shuō)做了決策結(jié)果就是確定的。
最后一個(gè)是Policy,這是比較重要的概念,它的意思可以理解為策略,就是面對(duì)當(dāng)前的狀態(tài),應(yīng)該如何做決策?
因此,一個(gè)policy,可以理解為從狀態(tài)到?jīng)Q策的一個(gè)映射。
比如狀態(tài)的集合記為S,決策(或者說(shuō)動(dòng)作)的集合記為A,那么policy就是一個(gè)S->A的映射。
Poliyc有確定性的,也有隨機(jī)的。
確定性的Policy很好理解,就是面對(duì)一個(gè)特定的狀態(tài)s,對(duì)應(yīng)有一個(gè)確定的決策a。
隨機(jī)的Policy意思是對(duì)于一個(gè)特定的狀態(tài)s,對(duì)應(yīng)的是一個(gè)決策的分布。此時(shí)可能是這個(gè)action,可能是那個(gè)action,不是確定的。
比如下棋,面對(duì)同樣的棋局,可能有幾個(gè)備選的方案,每次選哪個(gè)是隨機(jī)的,不是確定的。
應(yīng)該說(shuō),強(qiáng)化學(xué)習(xí)研究的問(wèn)題大部分都是隨機(jī)性的policy。

最后一個(gè)重要的概念是value function,這個(gè)會(huì)比較繞一些。
一個(gè)value function一定跟一個(gè)policy有關(guān),或者說(shuō)是關(guān)于這個(gè)policy的value function。
比如一個(gè)value function設(shè)為V,當(dāng)前狀態(tài)假設(shè)為s,它計(jì)算的是在一定的policy下,未來(lái)可以獲得的收益的折現(xiàn)求和之后的期望值。
可以看出比較繞,因?yàn)樗婕暗搅撕芏嗟碾S機(jī)性。
比如對(duì)當(dāng)前狀態(tài)s_t=s,未來(lái)可以采取的決策是多種多樣的,每種決策對(duì)應(yīng)的結(jié)果也是隨機(jī)的。比如隨機(jī)的policy,對(duì)于這種狀態(tài)s,它可以采取的action是隨機(jī)的;每個(gè)action下,得到的收益也是隨機(jī)的。這兩重隨機(jī)性要考慮。
還有就是折現(xiàn)值,這涉及到一個(gè)折現(xiàn)率discount ratio。為什么需要這個(gè)折現(xiàn)率呢?如果從金錢(qián)的角度,貨幣有時(shí)間價(jià)值,現(xiàn)在的100塊錢(qián),跟一年之后的100塊錢(qián),肯定不一樣;一年之后的100塊錢(qián)折現(xiàn)到現(xiàn)在要有一個(gè)折現(xiàn)率。一般來(lái)說(shuō),如果利率是r,折現(xiàn)率就是1/(1+r),所以,一般折現(xiàn)率是大于零小于1的,特殊情況可以取等號(hào)。
如果折現(xiàn)率是0,也就是未來(lái)收益不管多少都不算,只算當(dāng)前收益;
如果折現(xiàn)率是1,也就是未來(lái)收益統(tǒng)統(tǒng)都算,而且不需要衰減。
強(qiáng)化學(xué)習(xí)一般用于玩游戲,會(huì)希望不要做一些無(wú)用功。比如理論上一個(gè)小人可以左走一步右走一步,拖延時(shí)間,就是不去打怪獸,也不去吃果子。但如果有折現(xiàn)率,現(xiàn)在吃果子有100分,但拖到幾步之后吃果子只有90分,會(huì)迫使機(jī)器不會(huì)故意拖延時(shí)間。
當(dāng)然,折現(xiàn)率設(shè)置不好,也會(huì)影響結(jié)果。比如下圍棋,如果折現(xiàn)率接近1,可能會(huì)放著棋子就是不去吃,錯(cuò)失良機(jī);如果接近0,可能會(huì)類(lèi)似貪心算法,很快就吃,否則未來(lái)吃分?jǐn)?shù)就不高;因此,本質(zhì)上也是調(diào)參玄學(xué)。
好了,上面介紹了RL的3個(gè)組成部分:model,policy,value function,然后可以分成兩大類(lèi):model-based和model-freee。
model-based的意思就是會(huì)清楚知道模型,包括馬爾科夫決策模型,獎(jiǎng)勵(lì)模型等,都會(huì)給出來(lái);但可能并不知道policy或value function。
model-free的意思就是連模型都沒(méi)有,至于policy和value function,可能知道可能不知道。
比如俄羅斯方塊,其實(shí)就4種積木,每種1/4,狀態(tài)就是當(dāng)前的盤(pán)面形態(tài),因此狀態(tài)轉(zhuǎn)移概率矩陣是知道的,獎(jiǎng)勵(lì)模型也是知道的,這就是model-based,但我們并沒(méi)有policy,事實(shí)上我們的任務(wù)就是要設(shè)計(jì)policy來(lái)玩。policy都沒(méi)有,那么value function肯定也沒(méi)有的。
但絕大多數(shù)時(shí)候是沒(méi)有這么明確的狀態(tài)轉(zhuǎn)移概率的。比如下圍棋,狀態(tài)轉(zhuǎn)移i概率跟決策有關(guān)的,但肯定不知道對(duì)手如何決策,甚至決策的概率分布也不知道。這個(gè)不是隨機(jī)的。
俄羅斯方塊的概率分布是確定的,因?yàn)?種方塊每個(gè)出來(lái)的概率都是25%;但對(duì)于棋局,每個(gè)格子下的概率不是一樣的,可能這個(gè)高,可能那個(gè)高,不知道的。這種情況下一般可以蒙特卡洛模擬,比如AlphaGo用的蒙特卡洛搜索樹(shù)。
當(dāng)然,也可能不知道m(xù)odel,但知道policy的。比如現(xiàn)在高三,下一步讀大學(xué),我不知道能去哪一所大學(xué),這個(gè)概率不知道的;但我的policy是知道的,只能申請(qǐng)啊,只是不知道能申到哪一所。
當(dāng)然,哪怕model-based,也是需要蒙特卡羅模擬的。哪怕知道了狀態(tài)轉(zhuǎn)移的概率,也要按照這個(gè)概率不斷生成隨機(jī)樣本來(lái)研究。